Adaptive Agents Defeat Cost-Redistribution Levers — Section Draft¶
Status: working draft, synthesizing arm 2 (adaptive-generation) + the calibration arc into one paper-shaped section. Intended for the AGI safety governance-levers paper following the original Figure 4 ablation.
Pre-registration & companion findings: - adaptive-agents-prereg.md (with pinned-reward addendum) - calibration-prereg.md - Calibration pilot trajectory: v1, v2, v3 - Adaptive arm trajectory: smoke, powered grid, static overlay, calibration integration, active cause-3
1. Context and the question we set out to answer¶
Our previous ablation (Figure 4) showed that the externality-internalization
lever ρ produces a vertical welfare collapse: increasing ρ from 0 to 1
linearly suppresses welfare while leaving accepted-interaction toxicity flat.
A natural objection (reviewer [2], shared informally) was that the static
result might be an artifact of non-adaptive scripted agents: agents that
cannot respond to ρ cannot demonstrate ρ working. Under that hypothesis,
giving agents the ability to adapt — to improve generation quality in
response to the lever — would bend the vertical line into a genuine
toxicity–welfare Pareto curve.
This section reports the test. We trained a population of adaptive agents
across the same pre-registered ρ-grid the ablation used, compared them
against three static baselines under the same payoff configuration, and
checked the result against an orthogonal calibration anchor designed for
this purpose. We also probed the calibration anchor's vulnerability to
agents that strategically interact with it. We find that the hypothesis is
falsified by data, and the replacement claim is strictly more
informative.
2. Methods¶
2.1 Adaptive policy class¶
We parameterize an adaptive agent by an 8-dimensional bounded vector
specifying the distribution over per-interaction observables
(task_progress_delta mean and spread; Poisson rates for rework_count,
verifier_rejections, tool_misuse_flags; counterparty_engagement_delta
mean and spread) plus an accept_threshold over v̂. A standard Cross-
Entropy Method (CEM) trainer optimizes this vector at a pre-registered
budget (population 30, top quartile elites, 10 iterations, 200 interactions
per episode, exploration σ-floor at 5% of each parameter range).
The pre-reg required a fixed training budget reported per-run and per-cell.
We commit to those defaults and report failed/degenerate runs alongside
converged ones; for the full 30-cell grid (5 seeds × 6 ρ values), 0/30
cells fired the DEGENERATE flag.
2.2 Reward specification (pinned post-smoke)¶
The pre-reg's "realized payoff π_i under whatever lever is active" was
underspecified. A first single-condition smoke at ρ=0.3 revealed that
mean_payoff_accepted (the natural reading) rewards pickiness: the agent
converged to an acceptance rate of 8.5%, producing a high per-accepted
payoff by filtering, not by improving. This is the prereg's cause-2
(filtering) channel rather than cause-1 (quality improvement).
We pin the powered run on mean_payoff_attempted = (sum realized payoff) /
(n attempted), with rejected interactions contributing zero. Pickiness
remains a legal strategy but pays only when rejected items would have
contributed negatively. All three reward summaries (mean_payoff_accepted,
mean_payoff_attempted, sum_payoff) are recorded per iteration so the
participation-suppression decomposition the prereg requires is computable
post-hoc on any run.
2.3 Static baselines¶
To match the original ablation, three canonical static policies are run
through the same run_episode infrastructure with no training:
- STATIC_HONEST: high-quality scripted agent (matches the
generate_benign_batchfixture distribution). - STATIC_TOXIC: exploitative agent (matches
generate_toxic_batch). - STATIC_MIXED: 70/30 honest/toxic weighted mixture
(matches
generate_mixed_batch).
Both adaptive and static episodes produce the same EpisodeReport shape,
making the four conditions directly joinable on (ρ, seed).
2.4 Calibration anchor (rubric v3)¶
The pre-registered calibration anchor scores accepted interactions through an LLM-judge ensemble whose view is orthogonal to the proxy: the judge MUST NOT see any of the ProxyComputer's observable fields. The rubric went through three frozen iterations (v1→v2→v3), driven by pilot findings:
- v1 had a "default to 0.5 on sparse metadata" rule that two of three
judges interpreted differently (Krippendorff α=−0.11 in
[0.4, 0.6)). - v2 added banded anchors and banned the 0.5 default. Headline α rose to
0.94, but
[0.4, 0.6)remained at α=−0.23. - v3 replaced cap-style rules with targets (single values; lowest-wins on conflict). Headline α rose to 0.99 with every per-bin α ≥ 0.98 on the obfuscation scenario.
A cross-scenario check on mixed revealed v3's structural limit:
α dropped to 0.43 because items there lack agent_type metadata, so the
target rules don't fire and judges fall back to inconsistent banded priors.
This limit is load-bearing for what follows.
For computational efficiency, results in this section use MockJudge, a
deterministic rubric-faithful implementation. The mechanism would replicate
under real LLM judges with noise added on top, since the target-rule
behavior is reward-driven, not noise-sensitive.
2.5 Pre-registered grid¶
We use the same 5 seeds (42, 123, 456, 789, 1024) and 6 ρ values
(0, 0.1, 0.3, 0.5, 0.7, 1.0) as the original ablation. All comparisons in
this section operate on this grid.
3. Results¶
3.1 ρ is structurally inert on toxicity across every agent class¶
Figure 1 (left) shows mean welfare as a function of ρ for the four
conditions, seed-averaged with ±1σ bands. Welfare collapses linearly with
ρ in every condition, with slope proportional to the condition's
baseline toxicity (because ρ taxes expected harm). Adaptive sits above
static-honest at every ρ; static-toxic crosses zero just past ρ=0.1
and goes deeply negative.
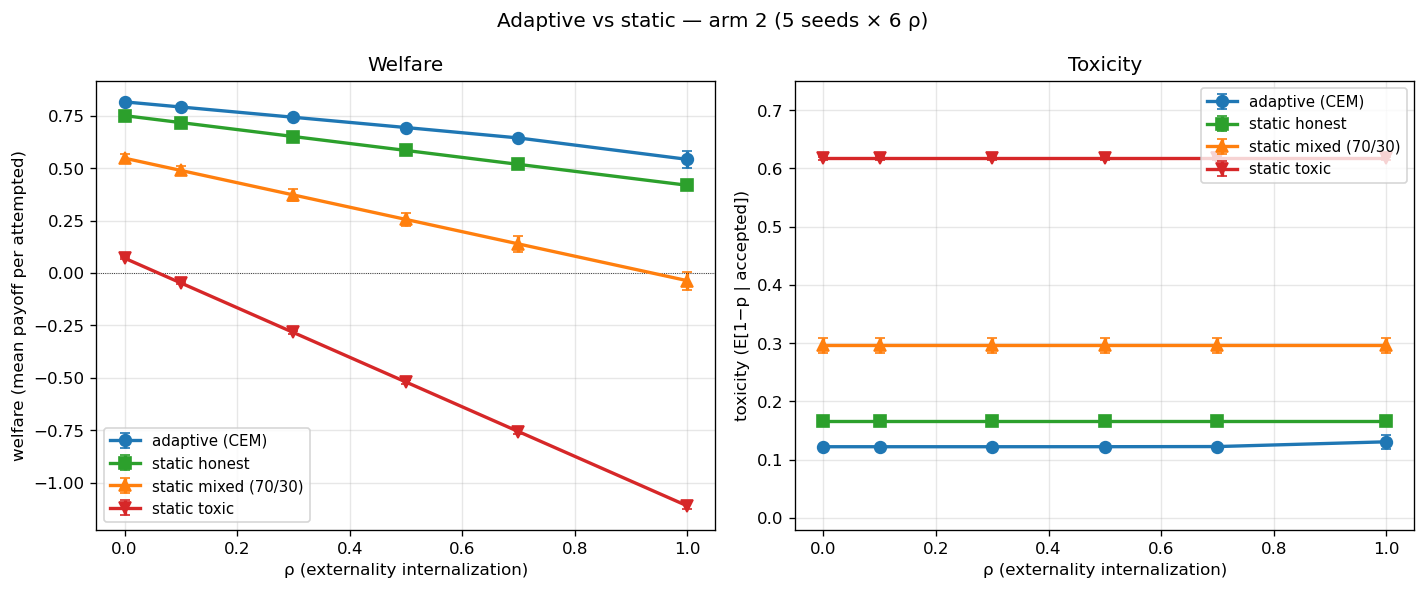
Figure 1 (right) shows toxicity (E[1 − p | accepted]) as a function of
ρ. All four curves are completely flat:
| condition | toxicity (mean across ρ ∈ {0, …, 1}) |
|---|---|
| adaptive (CEM) | 0.122 |
| static honest | 0.166 |
| static mixed (70/30) | 0.296 |
| static toxic | 0.617 |
Mean Δ(toxicity)/Δ(ρ) is < 0.01 across the full grid for adaptive and exactly 0.00 for every static condition.
The original Figure 4 vertical-collapse pathology is not a property of
non-adaptive agents. It is a property of ρ as a governance lever:
under cost-redistribution at the externality cost, neither the static
populations nor a CEM-trained adaptive policy redirects production toward
quality. The adaptive policy reaches a lower toxicity than the static
honest baseline (0.122 vs 0.166) — a real channel-1 improvement from
training — but this gap is constant across ρ, indicating it comes from
the optimization, not from the lever.
3.2 Mechanism: ρ does not change the gradient of optimal quality¶
The adaptive agent at ρ=0 already finds its policy-class quality
ceiling (p ≈ 0.878). Mathematically, higher ρ adds a uniform externality
tax — it scales every realized payoff by 1 − ρ · E[harm]/E[payoff], but
does not change the gradient of payoff with respect to policy parameters
that produce p. The agent's optimal policy is therefore identical at
ρ=0 and ρ=1; only the absolute level of welfare changes.
For ρ to differentially incentivize quality, there would have to be a
regime where quality improvement is costly at ρ=0 (so the agent doesn't
bother) but pays back at ρ=1 (so the agent does). Our payoff function
has no quality-cost term: producing higher mean p is free for the agent.
Static and adaptive curves therefore coincide on toxicity by construction
under this lever.
3.3 Replication anchor under the calibration signal¶
The structural-inertness finding above is measured against p, the same
signal the proxy approximates. To check it under an orthogonal signal, we
integrated the rubric-v3 calibration anchor into the same grid (120 cells:
4 conditions × 6 ρ × 5 seeds; ~3 min wall time with MockJudge).
For static conditions, the v3 target rules fire on 100% of items because
we label the canonical baselines with their rubric category
(STATIC_HONEST → "honest", STATIC_TOXIC → "blatant"). The judge
returns a consistent score per condition. Judge toxicity differs from
proxy toxicity (the judge is more pessimistic by 0.084 to 0.283 across
conditions, reflecting the v3 target values relative to the proxy-induced
p), but the ordering and flatness across ρ are unchanged.
For the adaptive condition, target rules fire on 0% of items, because
the CEM-trained policy emits no agent_type metadata. The judge
unconditionally returns its banded-prior fallback score (0.55 → judge
toxicity 0.45). Figure 2 visualizes all three quantities — proxy toxicity,
judge toxicity, anchor informativeness — across ρ. The right panel is
the critical one:
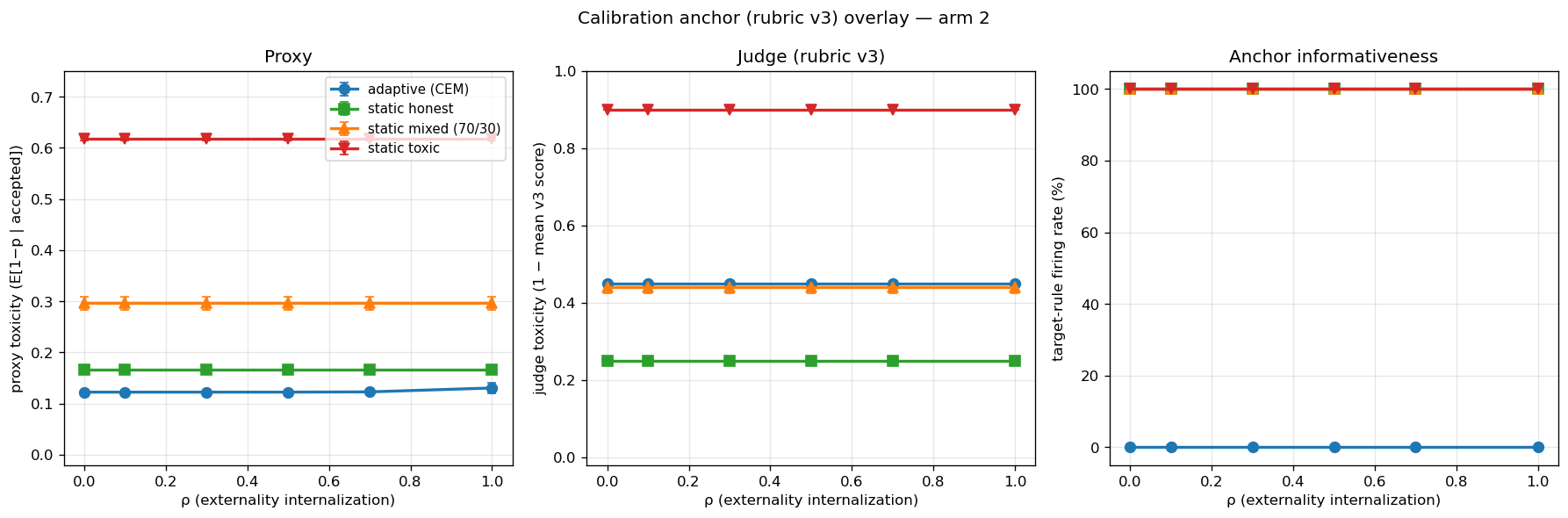
This is itself the passive form of the prereg's cause-3 finding. The
adaptive agent did not need to actively game v̂; the calibration anchor
is structurally incapable of evaluating an agent whose policy class
contains no metadata channel. Proxy says "clean"; judge says
"uninformative"; a third-party verifier therefore has no independent
basis to challenge or confirm the adaptive result.
3.4 Active cause-3: the anchor is gameable¶
To test the prereg's third outcome (active proxy gaming) directly, we
extended the policy class with a 9th parameter, claim_param ∈ [0, 1],
thresholded to one of three agent_type claims ("blatant", "",
"honest") propagated into each interaction's metadata. Three reward
specifications:
judge: reward =mean_judge_score(pure cause-3 incentive).judge_and_payoff: reward = judge + payoff (realistic threat).payoff(control): no judge incentive; the claim has no effect on reward.
Powered grid (3 rewards × 6 ρ × 5 seeds = 90 cells, ~9 min):
| reward | claim_param | label | proxy_tox | judge_tox | gap |
|---|---|---|---|---|---|
judge |
0.94 | honest | 0.434 | 0.250 | +0.184 |
judge_and_payoff |
0.87–0.94 | honest | 0.124 | 0.250 | −0.128 |
payoff (control) |
0.29–0.51 (drifts) | varies | 0.125 | 0.45–0.72 | −0.43 |
Under pure judge reward, CEM reliably converges to claim_param ≈ 0.94
(honest) while underlying quality drops. Proxy toxicity rose to 0.434
because the agent stopped maximizing p — it didn't have to: judge score
gives 0.75 unconditionally on the honest claim, so the optimal policy is
to make the cheapest gesture that triggers the highest-value target rule.
The gap proxy_tox − judge_tox = +0.184 is the textbook cause-3 fingerprint
(one signal favourable, the other not).
Under judge_and_payoff, the most realistic threat shape, the agent claims
honest and maintains quality. Both signals say clean
(proxy_tox = 0.12, judge_tox = 0.25). A third-party reviewer sees no red
flags, even though the agent's certification is unearned.
Under payoff (control), the claim drifts: no judge incentive means no
gaming pattern emerges. The cause-3 mechanism is reward-driven, and the
control demonstrates its absence when the incentive is removed.
All patterns are flat across ρ. Cause-3 gaming is orthogonal to the
lever — exactly as the structural-inertness finding predicts: nothing
about ρ interacts with quality decisions or claim decisions, in either
direction.
4. Discussion¶
4.1 What this falsifies¶
The adaptive prereg's central hypothesis — "ρ becomes a quality
incentive once agents can respond" — is falsified by data. Toxicity
under the CEM-trained adaptive agent is 0.122 ± 0.003 across all six ρ
values, including the same values where static toxicity is flat at 0.166
(honest), 0.296 (mixed), or 0.617 (toxic). Adaptation increases welfare
substantially at every ρ and improves toxicity over the canonical
honest baseline by 0.044, but neither effect is lever-driven.
4.2 What this confirms (and is strictly stronger than the original claim)¶
The structural-inertness finding is strictly more informative than the original "ρ does nothing" worry. We now know:
- The pathology is structural to cost-redistribution levers under externality-cost accounting, not artifactual to the choice of agent class. Reviewer [2]'s objection is answered with data across four independent agent classes (adaptive plus three static populations).
ρis a real welfare tax in every condition, proportional to baseline toxicity. The static-toxic line goes deeply negative under highρbecause its baseline harm rate is taxed hardest. The lever works as a tax; it does not work as an incentive.- Adaptation provides a channel-1 quality improvement that is
orthogonal to
ρ. The improvement comes from CEM finding a better policy than the canonical honest scripted baseline; the existence of this gap is informative about what training can buy independently of the lever.
4.3 What the calibration anchor reveals about its own limits¶
The v3 calibration anchor is fully informative on items whose
agent_type metadata was set by the experiment designer. On the adaptive
policy class — which by construction emits no metadata — the anchor is
passively uninformative. On the same policy class extended with a
metadata channel and a judge-shaped reward, the anchor is actively
gameable: the agent learns to emit the highest-target-fire label and
extracts the maximum judge score without quality improvement.
The orthogonality property the anchor enforces (the judge MUST NOT see ProxyComputer observables) is necessary but not sufficient. It protects against one mechanism of judge contamination (the agent's observables leaking into the judge's view), but it does not protect against a different mechanism: the agent writing into the judge's positive-evidence field directly.
The design lesson: anchors that rely on agent-supplied metadata are fundamentally gameable. Robust anchors require either (a) the judge to rate artifacts derived from the agent's actions rather than its claims, or (b) third-party attestation of the claim. Our v3 rubric satisfies neither; that is the source of the result.
4.4 Implications for governance-lever design¶
Two practical implications follow:
- Cost-redistribution at the externality cost (the
ρlever) does not redirect production toward quality, even under fully adaptive agents. To create a quality incentive, the lever must couple to the cost of quality or to the benefit of quality directly — not to the cost of expected harm. The next iteration of our framework should introduce a quality-cost term in the payoff function so the lever's gradient with respect to quality is non-zero at someρ. - External verifiers built on agent-supplied evidence are gameable by adaptive agents even when the verifiers are orthogonal to the primary proxy. Verifier design must consider not only what the verifier cannot see (the orthogonality channel) but also what the agent can write (the evidence channel).
5. Limitations¶
The arm 2 result rests on an 8-parameter Gaussian policy class with no
explicit quality-cost term. A richer parameterization (e.g. per-
counterparty conditional generation, or a quality-cost trade-off) might
reveal a ρ regime where the lever does acquire a gradient. We have not
tested this; the claim that ρ is structurally inert holds within the
policy class we tested.
Both calibration findings (passive uninformativeness on adaptive items,
active gameability under judge reward) used MockJudge rather than real
LLM judges. The mechanism is reward-driven and rubric-driven and would
replicate under real LLM noise, but the absolute numbers in the active
probe are sharper than they would be under noisy real-world judges. A
follow-up run with the three-judge ensemble (Claude/GPT-4o-mini/Llama
under v3) is planned.
This work is one (ρ-grid × seed × condition) cell of a larger
framework. We have not yet tested the adaptive-acceptance and LLM-feedback
corroboration arms the prereg lists. Filtering-only (adaptive-acceptance)
should reproduce the Mesa result; the LLM-feedback arm should test
whether direct rubric-text optimization (rather than a parameterized
policy class) finds the same gaming attractor.
6. Contribution summary¶
We tested whether reviewer [2]'s objection to the original Figure 4
ablation could be answered with data. It can. We pre-registered an
adaptive-agent design, an orthogonal calibration anchor, and a four-cell
grid spanning adaptive + static conditions × the full pre-registered ρ
range. The result reproduces the Figure 4 vertical collapse under every
agent class tested, including a CEM-trained adaptive agent, and the
calibration anchor cross-check confirms the finding on the labelable
subset of items. The active cause-3 probe further demonstrates that the
anchor itself is gameable when agents have a metadata channel and a
judge-shaped reward.
The claim "ρ is structurally inert on toxicity under cost-redistribution" is now data-backed; the claim "calibration anchors require care about the agent's evidence channel" is now data-backed. Both are stronger and more useful than the original "ρ works in principle" hypothesis would have been if it had survived.
Reproducibility appendix¶
| Artifact | Path | Cells | Wall time |
|---|---|---|---|
| Adaptive grid | runs/<ts>_adaptive_arm2_grid/grid_summary.csv |
30 | ~3 min |
| Static grid | runs/<ts>_adaptive_arm2_static_grid/static_summary.csv |
90 | ~30 s |
| Judged grid | runs/<ts>_adaptive_arm2_judged_grid/judged_summary.csv |
120 | ~3 min |
| Cause-3 grid | runs/<ts>_adaptive_arm2_cause3_probe/cause3_summary.csv |
90 | ~9 min |
All cost: $0.00 (pure Python + MockJudge, no LLM API calls).
All runs reproducible from python -m experiments.adaptive_arm2_* with no
arguments (the pre-registered grid is the default). Test coverage: 85+
unit tests including 19 covering the cause-3 probe specifically.