Threshold-drift: a once-calibrated alarm fails silently — and AUROC can't see it¶
Date: 2026-05-25
Follows: detection_tau_ablation.md (which conjectured soft's residual advantage is being "threshold-free / drift-robust").
Bottom line (two drift types tested): At the operating point, the conjecture fails — under location drift a once-calibrated alarm's detection rate collapses to ~0 for soft and binary alike, while AUROC stays high (rank-based, drift-invariant); neither detector escapes recalibration, and AUROC can't see the failure. But for discrimination under scale/compression drift, soft genuinely wins — its ranking is affine-invariant while a fixed-threshold binary collapses to chance. So soft's real edge is recalibration-free ranking, not operating-point robustness. (See the two sections below.)
Setup¶
Heterogeneous regime (proxy_noise=0.09), base rate 0.2, 8 seeds × 200 agents. We model proxy calibration drift: the monitor increasingly over-reports quality — every interaction's p inflates by 0.012 × (epoch − 6). Each detector's alarm threshold is calibrated once at epoch 6 (FPR ≤ 0.05 on benign), then held fixed. We track, over sliding 3-epoch windows, AUROC and the realized false-alarm rate (FPR) / detection rate (TPR) at that fixed alarm — with drift vs a no-drift control.
Detectors: soft toxicity, bin@0.50 (naive threshold), bin@0.78 (≈ class boundary, the best from the τ* ablation).
Results¶
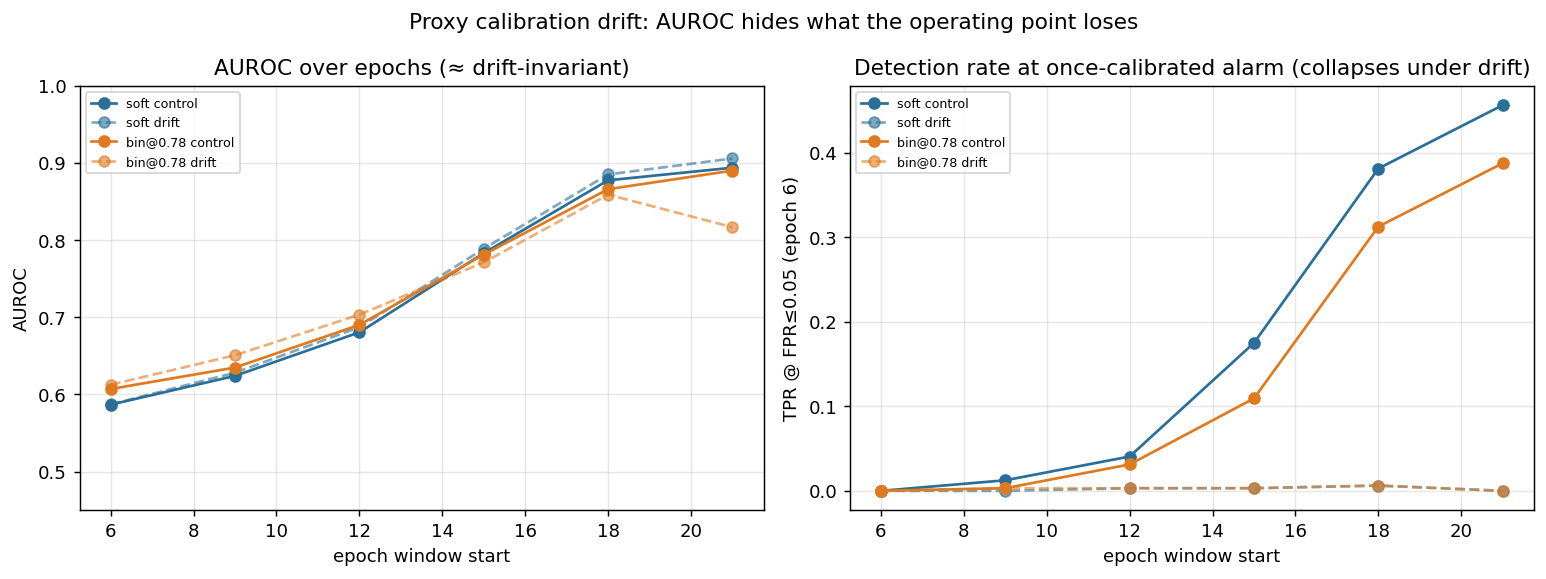
AUROC (control / drift) — discrimination is preserved under drift:
| epoch | soft | bin@0.50 | bin@0.78 |
|---|---|---|---|
| 6 | 0.587 / 0.587 | 0.499 / 0.500 | 0.607 / 0.613 |
| 12 | 0.681 / 0.687 | 0.515 / 0.502 | 0.690 / 0.703 |
| 18 | 0.878 / 0.885 | 0.596 / 0.502 | 0.866 / 0.859 |
| 21 | 0.894 / 0.906 | 0.601 / 0.502 | 0.890 / 0.817 |
Detection rate (TPR) at the once-calibrated alarm — collapses under drift:
| epoch | soft ctl / drift | bin@0.78 ctl / drift |
|---|---|---|
| 12 | 0.041 / 0.003 | 0.031 / 0.003 |
| 15 | 0.175 / 0.003 | 0.109 / 0.003 |
| 18 | 0.381 / 0.006 | 0.312 / 0.006 |
| 21 | 0.456 / 0.000 | 0.388 / 0.000 |
(Realized benign FPR under drift also drifts toward 0.000 — the alarm goes quiet, which looks reassuring but is catastrophic: it's quiet because it's missing everything.)
What this means¶
-
AUROC is blind to operating-point drift. It holds at 0.88–0.91 (soft) across the whole run, drift or not — because monotonic proxy inflation preserves the ranking of agents. Meanwhile the deployed alarm's detection rate falls from ~0.46 to ~0.00. A monitor can look perfect on AUROC and catch nothing in production. Evaluate monitors by realized FPR/TPR at the committed operating point, not by AUROC alone.
-
Threshold-drift robustness is not a soft advantage. Soft's committed alarm collapses exactly as hard as binary's (both → TPR ~0 under drift). The "soft is threshold-free, therefore drift-robust" idea from the τ note does not hold: soft has no internal τ, but it still needs an operating threshold on its score, and that threshold goes just as stale under drift. Both detectors require recalibration.
-
Combined with the τ* ablation, the soft-vs-binary story is now much narrower. With (a) the threshold placed at the class boundary and (b) regular recalibration, a binary detector matches soft on discrimination and fails/survives drift identically. Soft's genuine, remaining edge is convenience — one fewer threshold to tune (no internal τ) and automatic, drift-agnostic ranking* — not superior detection power or drift robustness at the operating point.
Update: non-uniform (resolution-loss / compression) drift — soft does win here¶
The location drift above is rank-preserving, so AUROC is invariant for both detectors by construction. The fairer stress is a scale/compression drift: the proxy loses resolution over time (the faithful analogue of sigmoid-k flattening), modelled as p' = 0.5 + (p − 0.5)·c(e) with c(e) shrinking from 1.0 to 0.4. This is not rank-preserving for a per-agent mean, so soft and binary AUROC can diverge:
| epoch | soft (ctl/drift) | bin@0.78 (ctl/drift) |
|---|---|---|
| 12 | 0.681 / 0.679 | 0.690 / 0.636 |
| 18 | 0.878 / 0.877 | 0.866 / 0.500 |
| 21 | 0.894 / 0.894 | 0.890 / 0.500 |
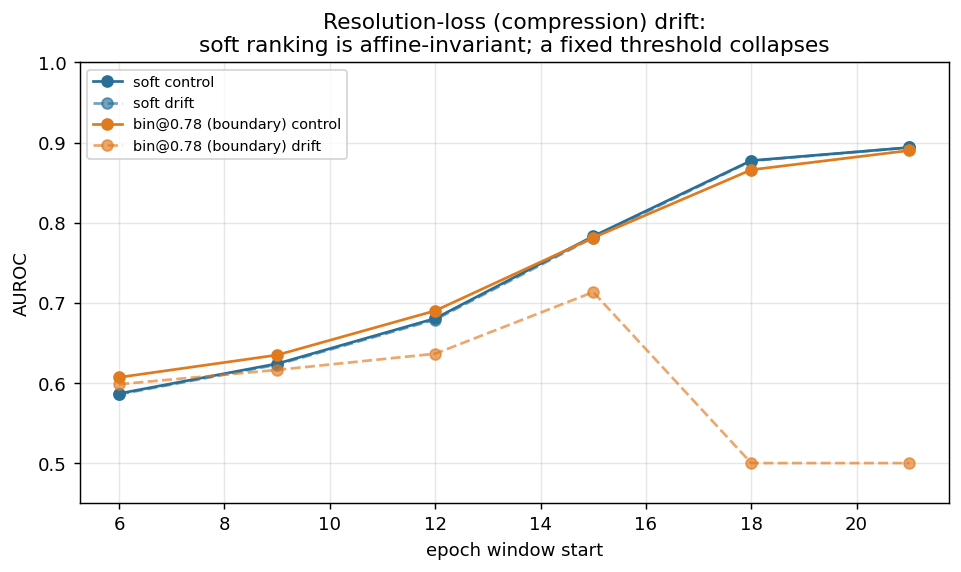
Soft AUROC is invariant (Δ≈0.000); the fixed-boundary binary detector collapses to chance. The per-agent soft score mean(1−p′) = 0.5 − (mean_p − 0.5)·c is an affine, order-preserving transform of mean_p with the same c for every agent — so agent ranking, hence AUROC, is unchanged. A fixed threshold has no such invariance: as the range compresses toward 0.5, both classes slide below 0.78 and the detector goes blind. (bin@0.50 is also invariant here, but only because compression preserves the sign of p−0.5 — and it's blind to begin with since both classes sit above 0.5.)
This restores a genuine, mechanistic soft advantage the location-drift result alone had hidden: soft's discrimination is rank-invariant to affine proxy recalibration (both offset and gain); a fixed threshold survives an offset (it just relabels the optimal τ*) but not a gain change. A threshold must be re-placed when the proxy's scale drifts; the soft ranking need not be.
Synthesis across the three ablations¶
- Discrimination (AUROC), static well-placed threshold (
detection_tau_ablation.md): binary ≈ soft, and binary can beat soft at higher noise. No soft advantage. - Discrimination under affine recalibration drift (this note, compression): soft wins — ranking invariant to proxy offset+gain; a fixed threshold collapses under a gain change.
- Deployed detection at a committed operating point under drift (location-drift result above): neither wins — both alarms go stale and miss everything; recalibration is mandatory, and AUROC can't see the failure.
Net: soft's real edge is recalibration-free ranking robustness, not superior raw power and not a free pass on operating-point monitoring.
Caveats¶
- Both drifts are uniform across the population and applied as post-hoc transforms on
p; a per-agent or adversarial drift could differ. - Single drift rate per condition;
bin@0.78uses an oracle-ish boundary threshold. - The control TPR rising over epochs is just degradation deepening (onsets 4/8/12); the drift-vs-control gap is the clean signal.
Implication for the blog post¶
Together with detection_tau_ablation.md, this strongly indicates docs/blog/soft-vs-binary-detection.md overclaims. An honest reframe:
- Soft's advantage is convenience and threshold-free ranking, not strictly superior detection — a boundary-placed, regularly-recalibrated binary detector is competitive.
- The real operational lesson is operating-point monitoring + recalibration under drift, which no detector (soft or binary) escapes, and which AUROC benchmarks hide.
I'd recommend a dedicated "limitations / what we got wrong" follow-up rather than quietly editing the headline numbers.
Reproduce¶
/tmp/drift.py in the PR description, or: calibrate each detector's alarm at an early window (95th-percentile of benign scores), inflate p by DR·(epoch−E0), and compare realized TPR/FPR and AUROC across later windows with DR>0 vs DR=0.