Adaptive adversary: soft constrains the mean; a threshold can be shaped around¶
Date: 2026-05-25
Follows: detection_tau_ablation.md (a well-placed threshold matches soft on static discrimination) and detection_threshold_drift.md.
Bottom line: Against an adversary that optimizes against the detector, soft has a genuine, mechanistic advantage that a well-placed binary threshold does not. Lowering mean quality, soft ≈ binary@boundary. But the binary threshold can be gamed by shaping the output distribution — a tight distribution sitting just above τ* evades it while preserving real quality loss; soft catches that because the mean still betrays the degradation.
Setup¶
A "settled" adversary games its benchmark (stays accepted) and holds its true quality constant within each run — it has already chosen where to sit. We sweep that chosen level across conditions to trace the evasion frontier. Each detector's alarm is calibrated to FPR ≤ 0.05 on benign (quality 0.85). We measure the catch rate (TPR) as the adversary varies, across conditions, (a) how far to lower its (constant) mean quality, and (b) how tightly to control its output distribution. 6 seeds × 60 agents, proxy_noise 0.09 for benign.
Result A — lowering mean quality¶
Catch rate vs the adversary's sustained true quality:
| true quality | soft | bin@0.50 | bin@0.80 |
|---|---|---|---|
| 0.50 | 1.00 | 1.00 | 1.00 |
| 0.65 | 1.00 | 0.98 | 1.00 |
| 0.70 | 1.00 | 0.71 | 1.00 |
| 0.74 | 1.00 | 0.33 | 1.00 |
| 0.82 | 1.00 | 0.02 | 1.00 |
- soft and bin@0.80 catch the adversary at every quality below benign — to evade either, the adversary must hold quality ≈0.85 (benign), i.e. inflict ~no harm.
- The naive bin@0.50 is evadable: the adversary can sit at ~0.72 and slip under the alarm, hiding ~0.13 of quality loss. (Same lesson as the τ* ablation — 0.50 is the wrong threshold.)
So against a mean-lowering adversary, a boundary-placed binary threshold is as robust as soft.
Result B — shaping the distribution (the real exploit)¶
Now the adversary fixes mean quality at 0.81 (genuine harm: below benign 0.85) and instead tightens its output distribution to avoid threshold crossings. Catch rate vs the adversary's output noise:
| adversary output noise | soft TPR | bin@0.80 TPR |
|---|---|---|
| 0.090 | 1.00 | 1.00 |
| 0.050 | 1.00 | 1.00 |
| 0.030 | 1.00 | 0.97 |
| 0.015 | 1.00 | 0.18 |
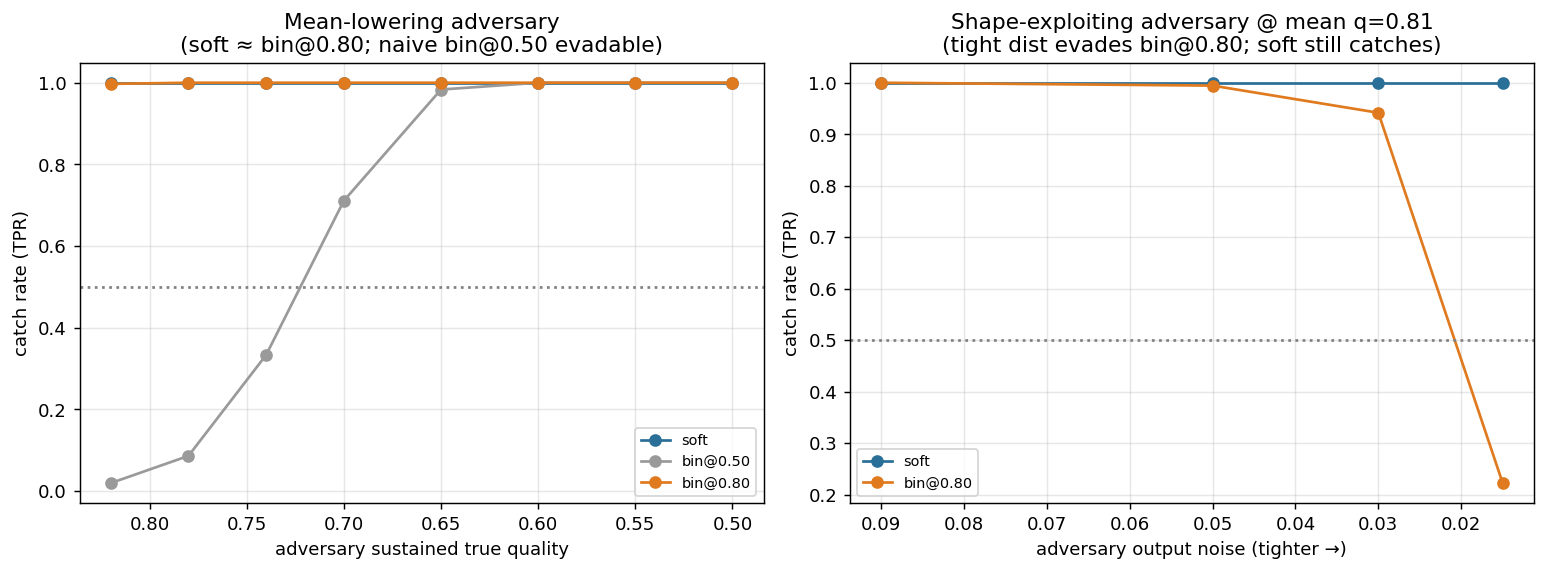
The tight adversary evades even the well-placed binary threshold (TPR → 0.18) while soft still catches it (TPR 1.00). A distribution concentrated just above τ*=0.80 produces almost no p < 0.80 crossings, so the threshold-counter sees a near-benign rate — even though the mean quality (0.81) is clearly degraded. Soft scores mean(1−p) ≈ 0.19 > alarm 0.151 regardless of spread, so it cannot be fooled by shaping.
Why this is the genuine soft advantage¶
A threshold detector measures a crossing rate, which depends on both the mean and the shape of the distribution near the threshold — so an adversary with two degrees of freedom (mean, spread) can hold harm constant while driving the crossing rate to benign levels. The soft mean has one thing to satisfy: to look benign you must be benign on average. The only way to evade soft is to actually raise quality — which is exactly the behavior you wanted.
This is robust to adaptation in a way the τ result is not: tuning the threshold to the boundary closes the static gap, but not the shaping* gap.
Synthesis across all four ablations¶
| Stress | Winner | Why |
|---|---|---|
Static discrimination, well-placed τ* (tau_ablation) |
tie (binary can beat soft at high noise) | threshold ≈ as discriminative as the mean |
Affine recalibration drift (threshold_drift, compression) |
soft | mean ranking is gain/offset-invariant; a fixed threshold isn't |
Committed operating point under drift (threshold_drift, location) |
neither | both alarms go stale; AUROC can't see it |
| Adaptive adversary, shaping (this note) | soft | a threshold's crossing-rate is gameable by distribution shape; the mean isn't |
Revised conclusion: soft's advantage over a well-tuned, regularly-recalibrated binary detector is not raw discriminative power — it's (1) recalibration-free ranking under proxy drift and (2) robustness to adversarial distribution-shaping. Both are real and safety-relevant; neither is the "thresholding throws away the signal" story we started with. The blog Limitations section should gain a line on the adaptive-adversary result.
Caveats¶
- The adversary here is static-optimal (picks a fixed mean/spread); a fully reactive adversary vs an adaptive defender (recalibrating τ*) is the next step.
- Single proxy-noise baseline; the shape exploit assumes the adversary can control its own output variance, which maps to a real agent producing consistently-mediocre-but-never-terrible work.
Reproduce¶
/tmp/adaptive.py (mean sweep) + the shape-exploit snippet in the PR. Core: calibrate each detector's alarm on benign (95th pct), then score constant-quality gaming agents at varying mean and output noise; report catch rate.